Fast development or future-oriented development?
Tech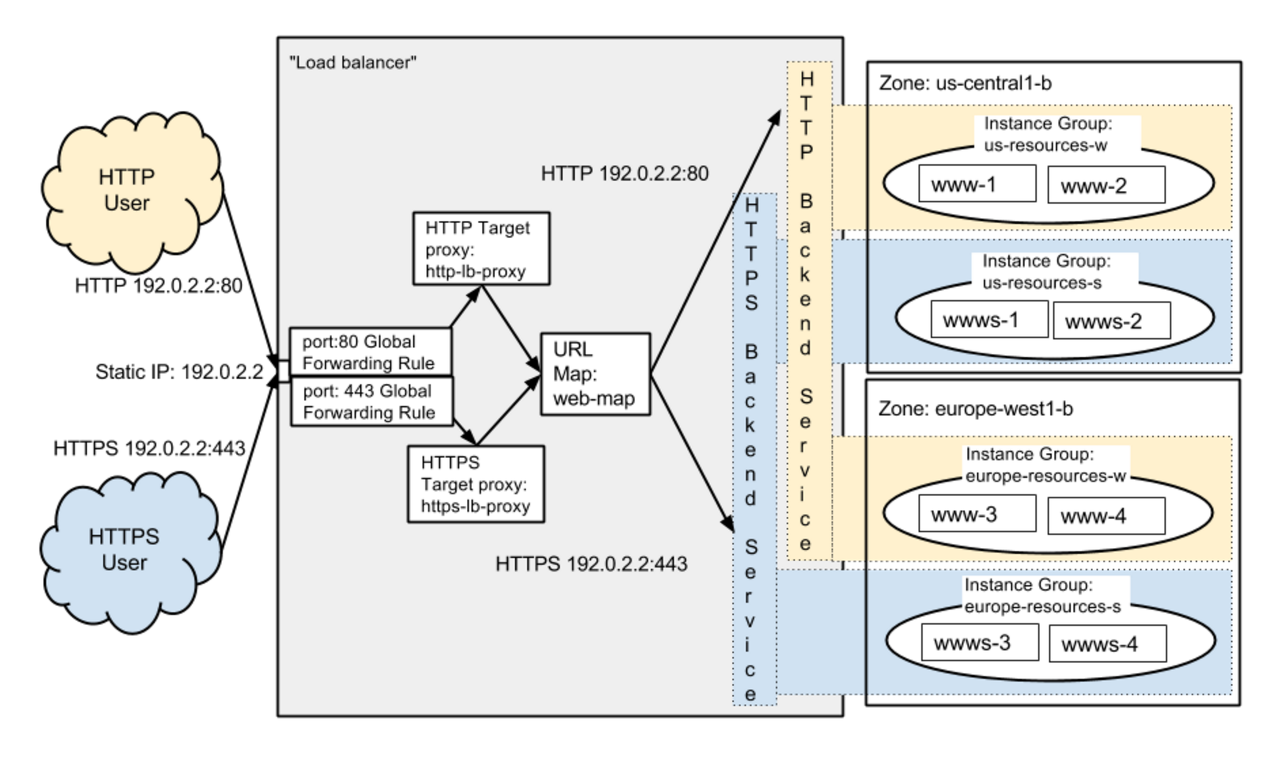
When I think about development, I feel that the most important part is whether I can get the maximum possible operation with minimal resources and prepare for large scale. That’s why I chose the micro service architecture, and if you automatically scale the resources used by the Docker to match the global, you will not worry about server extensions or co-location.
So far, if you really use AWS, Google Cloud Platform (GCP), and other cloud services, it’s much more stable than traditional bear-metal servers and dramatically increasing cost and resource efficiency. The best thing to do is to design the development and operating environment for Devops in the true sense.
The real meaning here is the least individual/small service, I think so. In my case, I am creating a global service, and I am not really worried about service architecture once or twice.
Just as the usual web service is, the bottleneck or not depends on the structure of the service. Minimizing bottlenecks is just as important as maximizing multi-core or GPU operations in game development, because the most important element of the web I think is ‘speed’.
Furthermore, we can not exclude business-related factors because we run startups. In other words, we are need to consider cost, schedule, security, localization, and legal issues. In particular, from a cost perspective, using the cloud, or IaaS in short, would mean increasing the flexibility of anticipating server installation to the performance of auto-scaling.
Well, using AWS Elastic Load Balancing is, well, frankly, it’s a little bit hard for startup costs to use. I have used Google Cloud Platform for about 3 years as an alternative, and now I am doing Docker orchestration using Kubernetes in earnest.
In this post, I’d like to write about “rapid development” that I think, design, use and worry about these days. In particular, Google’s investment in micro service is really noteworthy. I was honest with Kubernetes about its ease of use (Amazon’s ECS still feels a bit difficult). However, as a result of testing, scale up/down of replications through YAML is very fast. While the convenience and management of Docker’s private repositories is easy, the process of distributing version control in YAML files has worked so smoothly so far.
More specifically, even a simple fix with a hot fix will take less than 10 seconds to experience the process of destroying and recreating pods (a docker image pool in Kubernetes), rolling update from a server with a minimum connection, Is possible.
I run this process through the Gitlab CI and run the test case only in the master branch, then set it to be deployed as the latest tag in the repository. And then we do a rolling update with a simple kubernetes’ command.
Perhaps the most important thing in development is to think of ‘users’. While always developing, the UX and the functional aspect of the service are the most important, but at the same time they are very sensitive to the speed of the service. I feel great when I hear that the service is fastest from my wife, who is the biggest QA of my life, but can the service be operated fast even if the number of users increases by 100 persons, 1,000 people or 10,000?
Rapid Prototyping seems to be really hard because of that idea. To be honest, if I develop with Spring Framework with MyBatis, JSTL and Velocity (not considering UX or any architecture) in the same way as I did before, I think it will be developed soon. There are quite a lot of libraries I had collected in the past. If I hardcoded the backend code in MEANStack, LAMPStack, JSP, or HTML, it seems to be developing faster.
However, I do not like that kind of hard coding, and it does not fit with recent trends. Obviously, a bottleneck will surely occur in the future. So I have been using Play Framework with Scala, which is based on asynchronous operation for three years. Although RDB itself is not asynchronous, Slick (Functional Relational Mapping for Scala) and other DB libraries support asynchronization in a way that does not break the RDB structure when using MySQL.
As a result, I do not think that the backend is as slow as the asynchronous based server, and if the task is in the asynchronous pool of the backend in terms of allocation, the allocation of the container is increased so much that the utilization can be easily measured. So the load balancer has the advantage of easy scale up as well, and if I increase the checking cycle to a bit more, I can make more flexible contrasts, so I can also prepare for large scale. On the other hand, the DB itself is felt through the replica through the division of the insert/select, and it is also possible to ‘prepare’ for the large scale. GCP also easily supports replica of related-DB in intuitive UI.
In terms of server operation and distribution, my service is based on the backend as a play framework and the frontend as a base based on the Node.js with Express based on AngularJS, which can also be easily packaged into a container and automatically set the load balancer.
But the problem is now more complicated to set up the load balancer globally. There is no longer an automatic feature using the Kubernetes or GCP’s UI. The problem I’m facing today is that the GCP has recently come to Cloud CDN, so even if there are multiple instances of the same entity, the ip of the global zone will detect any group that contains them and proxy again to that region’s ip do.
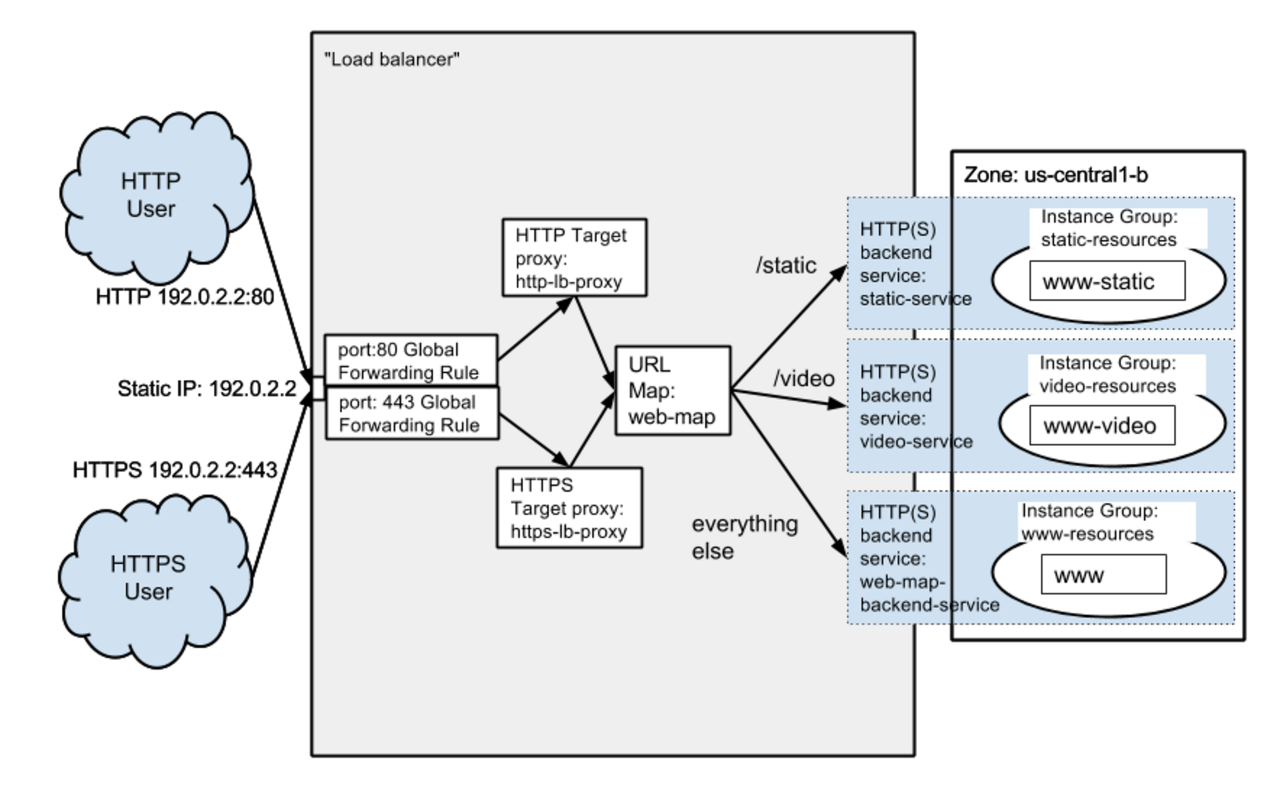
Personally, I like this structure quite a lot. But there are also drawbacks. In the case of an automatically generated load balancer through Kubernetes, load balancing based on HTTP(S) based on TCP (layer 4) is not yet applicable. To do this, layer 7 (the HTTP protocol) must eventually be pulled into Kubernetes’ service, and I could not find a way around that. In fact, if I consider the security aspect, I have to apply SSL, but if I want to make it easy for Google, I have to apply it within the HTTP protocol too. Whether it should be in a load balancer or in the backend (Netty for backend and Node.js for frontend) is still a big deal.
The key here is to continue to develop ‘future-oriented’, and when we are dealing with it, we are not progressing progressively compared to milestones, and problems continue to arise. I thought it was the fastest development at the heart of startups, but in fact, if there is no stable service, I wonder what it would be useful to do when it actually opened. The bottom line is that we have to balance the rapid development and the future development, and we have to continue to study for that.
There are so many unexpected paperwork in business these days. Future-oriented development seems to be like that. I do not expect everything, but in the end it is a must for stability. What is different about paperwork? Anyway, whatever it is, it seems to be a service of startup that it is necessary to prepare and make more than a certain grade, and it is thought that it is not as much as not doing it unless you do it. Still, the schedule should be reduced as much as possible.
As long as I have the pride of being a developer or a Devops, I will try my hardest to make stable and fast service.
The Tech industry evolves and improves day by day, but there seems to be so much to study. Even if it is prepared so hard, there may be zero user, or the problem may occur anywhere. But as long as I have the pride of being a developer or a Devops, I will try my hardest to make stable and fast service.